Apocryphal ocean
Too Long Don't Read
The National Aeronautics and Space Administration (NASA) Jet Propulsion Lab (JPL), specifically the Physical Oceanography Distributed Active Archive Center (PODAAC) wants to know how to access, analyze, and visualize signature assets.
I propose and justify web components (by which I mean services, workers, databases, applications) which enable consumers and processors to extract spatial subset(s) from these data, and build on-demand time series and derived products.
There won't be diagrams or benchmarks. Smarter folks have published digital reams on the subject of hypercubes and efficient access to multi-dimensional data.
The creators of some of the longest operating data acquisition software asked how to use the web to deliver these capabilities.
JPL engineers remotely diagnosed and patched Voyager in flight, on hardware with 70kb memory, when the computers started talking gibberish due to a single bit flip 33 years into the 48 year mission. I can't do that! Can I? Didn't Reed-Solomon, Galois fields, and RAID come from those projects? It's humbling to say, the “best” way depends on your use case, volume, budget, and charter.
The important part is thinking about how you want technology to drive your business outcomes in advance. There's just a ton of hard work to do before any code is written for the perfect future-proofed, warehouse-mart-lake-archive-repo-database. If you want a cheat sheet, here you go:
- If you're a service provider, write cloud native functions that access objects
- If you're a banker or risk professional, pay the Scala premium
- If you're an artificial intelligence platform, build a vertex graph with spatial partitions
- Else ship platform-independent assembly that produces data
The premise is trust
The key to making use of (dis)connected data, is to put it in context.
That requires developing a lingua franca for humans and machines. Let us start by ensuring we are on the same page.
Are there such things as one-dimensional ocean data? 🎙️
A single observation, without a location or timestamp is of little utility. This observation is probably a view into a series or spatial collection.
For an isolated system, like a sensor in water or fuel tank, you can fib and say “it doesn't have spatial dimensions”. Just time and whatever observed property you're measuring. 2-D. You can do the same fiction for any thing that doesn't move. A weather station, a box model, a buoy.
But as a system, these don't make sense without space and time. Things move, and if your schema assumes a fixed location, you prevent or complicate a whole line of services people would be happy to pay for.
All data are static, spatiotemporal graphs. 🙄
Meaning, data have location and time dimensions, and relationships to other data. No need here for arcane incantations of the third-normal form. 😱
Data do not change, and if they do, “the truth” changed. How you design for that says a lot about you. That is the topic of this talk.
Synthesizing data is sometimes called sensor fusion in terms of the mathematics, or increasing the data readiness level in terms of the process (Neil Lawrence 2017). I prefer "synthesis", because it acknowledges that we inject fiction (“models”) to increase the utility to the end user.
We invent semantics like "port forward fuel level sender" to refer to a precise location w.r.t. your Lagrangian reference frame.
When the reference or observed thing moves, we get a trajectory, which probably has at least four dimensions. Like a fish, boat, or πλαγκτός.
What we call 2-D (a gray-scale image) is 3-D: X,Y,Z. A wave height field, sea surface temperature, or centimeters of equivalent water based on “gravity sensing” satellites.
What we call 3-D like a point cloud, mesh, or volume rendering, is at least 5-D when animated, and a graph is a particular projection of a sparse matrix.
The examples of observed properties are contrived, because the true phenomena of interest are not captured.
Waves need frequency domain data, temperature varies with depth, and the water depth values come with many caveats.
It's bytes representing some few measurements. This becomes evident when you get into first principles of digitized voltages or photon counts. Sometimes a proxy is derived from two or more primary or derived properties.
When it comes down to it, we are doing pixel manipulation on discrete and reduced array representations of higher-order data or models.
What is a model? 🎙️
Ask some modellers and you will get that many answers:
- finite element mesh on which the numerical kernels run
- input data that represents what we believe to be truth
- fiction we encode in the source code
- the compiled binaries that actually run
- output produced by the action of running the kernel on the inputs and mesh
- whole system of data and assembly
- statistics or neural networks
To me, it is a magic trick that extracts knowledge from raw data and reduces uncertainty.
To make data useful to the public, we perform destructive actions. We create apocrypha, which are treated as canon.
Some actions are invisible, such as rounding and truncation errors and binning which over many iterations have economic and climate justice implications. And, unless you are the producer, it is often impossible to reverse engineer or reproduce the science. Only to appeal to authority.
Who should get to decide which interface encodes that hysteresis? 🎙️
Back-tracing (decoding) models is a really interesting topic. It is “just” reversing a physics-derived hash with deep neural nets, and I “only” need $10M, a team from “MIT and Stanford” and about 5 years. Trust me. I am the expert. 🤣
We have to trust that everyone in the pipeline is trained, awake, good-willed, and alert that day:
- “Human error…”, why an engineering control called a blowout preventer did not
- “Our algorithms function perfectly, but…”, federal agency on the timeless law of 🚮-in-🚮-out
- “Our code is correct…”, researchers setting an entire bio-region back >500K person-hours, disk capacity worth $20K/month, and >10K supercomputer hours.
To me it feels like dead code and black boxes. I felt like this for a long time, so, I taught myself “software engineering”. Today I can spin up a distributed supercomputer in a few minutes that will run anything I can imagine and afford. This is not because I am particularly good. It is because I use automated infrastructure built by smart people that enables me to do work that once took a team of five.
Innovation is a often signal of frustration by folks who wish into existence technology to accomplish certain tasks and express themselves inside a larger mission or organization, because they have trouble accessing support.
Reiterating my earlier point: the model is everything, organizations and individuals included. When we focus on frameworks, cloud providers, languages, libraries, and even standards we limit their possibilities.
Infrastructure as code means code is infrastructure. Source, infrastructure, binaries, artifacts, and “data” are Data. Capital-D Data, not Big Data.
Observable all the way down, so mote it be.
When that is so, communities of practice will align around brands and products, because they comprehend the ways in which their contributions drive desirable outcomes for themselves, the org, the community, and the planet.
Trust is the premise.
First date jitters
I like to document my first date with new data providers.
This is as far most people will get. One chance to make an impression. I am “reasonable”, so I will “allow” five (5). 💅
I mean, Tellus is a mother and provider, keeps livestock, and seems to like lounging in the woods with folk into astrology astronomy. #goddess

It is Art! It is also Tiles!
I arrive on the mission page. Looks slick. 😍
I learn GRACE stands for Gravity Recovery and Climate Experiment. It has a history of the project, some facts, and many links to external pages, even other catalogs.
Some links are broken. 💔
Fire up redundant systems and prepare for launch, 100% 🎙️
I instead search for the PODAAC site. The page I end up on suggests the mission is over. But I know there are newer data. Oh, -FO means follow on!
I am still learning about missions not data. 💔
We are experiencing some unpredictable turbulence, 90% 🎙️
The datasets have digital object identifiers, which is great. Plus citations and cross-referencing. Even better, it is a graph! 😍
Still, finding the right data set out of 109 variants is not easy, and the search is only by exact string matching. I try three times before I find the asset I want. 💔💔
Control, our navigation computer is acting up, 80% 🎙️
When I try the first download option I learn drive and language tools are private. Just sign up? Moving a little fast don't you think? Do you salt passwords? Where does SSL terminate? The running list of my leaked personal data is very long. 💔
We are getting cross chatter on our designated frequency, 70% 🎙️
We make some more Smalltalk about ASCII metadata and stories, before I commit and download the 800MB NetCDF. This takes ~3 minutes. I am actually not sure how long, because I get bored and start looking my phone. Recommended time-to-interactive is 2.2 seconds. 💔
Controls are sluggish, maybe we should abort the mission, 60%🎙️
“If you wannabe my lover, you gotta get with my friends…” including UCAR, HDF, USAF, Java, Python, BLAS, LAPACK. I could’ve spoken to Tellus via THREDDS, but then I have to XML. 💔
Your analogy is breaking down, 50%🎙️
So we stop!
I picked N=5 because that is when I got bored, and retroactively applied a restriction. I can make myself be not bored, but be honest about average user patience.

Why the Spice Girls (1994)?
Allow me to deflect by asking the question posed by content creator Brianne Fleming.
What can the Spice Girls “teach us about brand purpose”? 🎙️
We're getting to a point, I think
The Tellus asset I am talking about is TELLUS_GRAC-GRFO_MASCON_CRI_GRID_RL06_V2.nc.
Data are stored in NetCDF, and the files can be remote mounted or downloaded.
NetCDF is built over the hierarchical data format, and implements fixed chunking to optimize query performance for time slicing (usually).
Units are equivalent water thickness (cm), the coverage is global with 30 arc minute “grid”, and a one month sample period from April 2002 to the present.
There is a complimentary land mask, which can be used to extract either land or water features.
Here are some of the gotchas:
- Despite assertions, not a true “grid”, pixels are element-wise and offset from Null Island 🏝️
- Only sort of static until mission is over
- Chunking makes single pixel time series the worst case performance
- Have to read the metadata to know array offsets, endianness, and index order
I have had the pleasure of implementing performance-critical services and libraries to access similar data four or five times. I do not feel great about the results.
Not so much technical mistakes, as social constraints I didn't quite grok or couldn't negotiate.
Academic research was producing derived temperature and color data from Landsat, at 30m resolution using MATLAB.
I extracted the kernel that performed AVHRR and Landsat regressions and sensor fusion, and re-implemented the manual pipeline with numpy and docker. Oh hey fortran, I didn't see you hiding under that numpy.
It was hacky academic data science code that did file sync from file transfer protocol and remote mounted NetCDF. Servers, file systems.
What are database indices and partitions? Can I “just” use timescaledb and rasdaman? 👶
But I got a few things right!
- Kubernetes was just becoming, but declarative infrastructure made a lot of sense
- I took array chunking seriously
- I used lazy task tree execution
Here's a sketch of satcdf:
Python → FTP → NetCDF → Numpy → Rasdaman?
Passed the project on and moved to the Bay Area. Worked in regulated markets, because quality control and security, thinking I knew what I was getting into. 😅
How do you do billion-row searches and reductions on event-sourced data to build spatiotemporally-aware debt ledgers with zero accounting errors...
Parquet, and auto-scaling infrastructure in the shape of compliance-guard:
Python API → Postgres → GKE → Parquet → S3 → Python API → React

OceanTech is taking off, and I do both those things! You want me to take public data and improve it 8% with data synthesis and sell it at a premium? So cool! You want redundant stores of all data ever produced from the tape archives of multiple space consortia? Sounds expensive, we can do it with STAC and COG! 🙂
Next week please, in Java, and don't worry about review or tests. We have two APIs and four guerilla visualization projects, none are stable or documented.
Okay, here's a heads-up!
NetCDF/GRB → RabbitMQ → EKS → PostGIS → Python → Apollo → React → MapBox

I even drew a cute plesiosaur logo for it. Plesiosaurs are not cute, that was the point.
These examples are more complex than the directed acyclic graph I choose to show. Sometimes cyclic and bidirectional. The closer you fly to the Sun the more stuff there is. 🥵
That is OK, i.f.f. you can internalize all of the complexity, without making it inscrutable. But you ought not way-find for great ships unless you can propagate errors through the whole system.
There is no amount of click-wrap that can protect you from tort in the event of an Ever Given.
From the Louvre!

Icarus is not me, only a metaphor, the sun is Oracle or something. Dude just wanted out of prison. Probably would've helped to have altitude κυβερνάω and a 3-axis Honeywell magnetometer.
There is no secret to moving away from complexity. You just decide to keep it simplex, fast, and cheap and evaluate what you really, really want. 🌶️👧
The pattern I go to for unstructured vector data at oceanics.io is:
NetCDF → Lambda → Vertex Buffers → S3 → Neo4j → Lambda → WASM Worker → React → MapBox
It's not simple, but it is Simplex.
The data must flow
This is a well-loved asset and there is a ton of prior art. One-off “3-D” visualization goes back to 2003 and to 2013ish.
There are currently 2 web visualization and “analysis tools”. Both built for GRACE though they could be applied to any similar assets.
First, an absolute classic OpenGL fixed rendering pipeline artifact with Phong shading circa 2003:
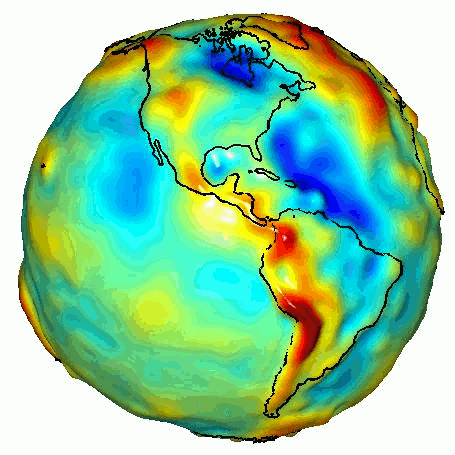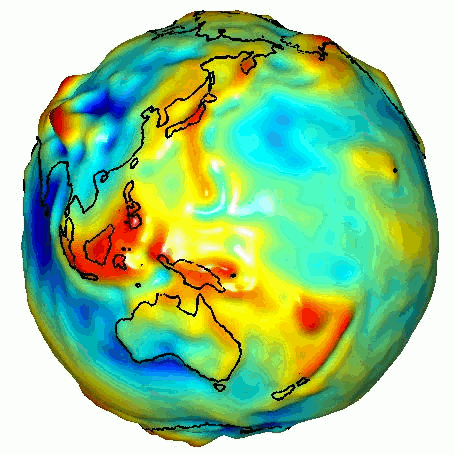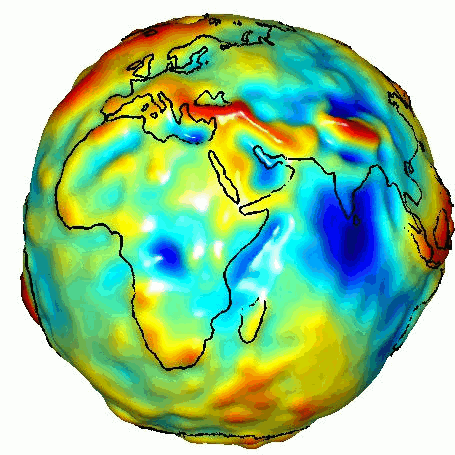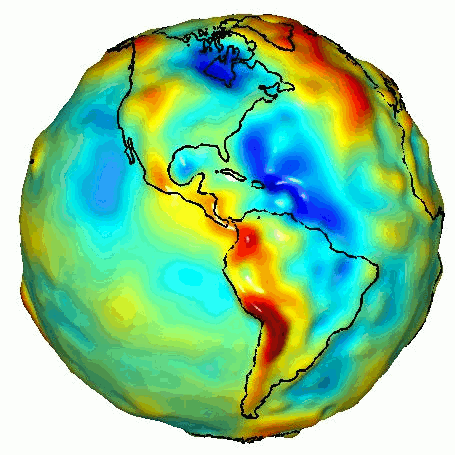
It can be securely embedded in documents. And it is vivid.
This video from the Goddard studio has aged less well.
In terms of interactive media, there is a JPL hosted one using react, Web Workers, and presumably webgl to render.
It looks good, is mostly bug free, and lets people waste their own time picking the color of the bike shed.
University of Texas has a Cesium-based version. Which does the same thing, but with a different engine and projection. www2, no https.
Based on how bogged down my browser gets, it is loading and transforming on the main thread.
Hexagons are cool! But the only way you are getting that is from lossy bi-linear sampling, that might change interpretation. The color map is problematic in terms of color blindness as well.
I can nitpick with the best, but I think these are amazing! They are Lagniappe, something extra.
Try inviting gov't employees to tech events. Most decline because they are too busy, but 100% of those that do show have actionable ideas worth pursing in the private sector.
These agile developers and guerilla capacity planners are one of your most valuable resources, because they care enough to do it anyway, for “free”.
Their efforts are actually part of the total cost of ownership, though not accounted.
It is apparent to me that internal orgs own parts of the GRACE process, and the goals of PODAAC are distinct from those of say UT, JPL, or NASA.
What would be a way that the Tellus legacy could become about spanning boundaries? 🎙️
Delivering visualization that is accessible and maintainable and beautiful, is a long road.
Even trying to mandate standards can distract from the core mission. Community standards crop up when tech starts to outpace standards orgs.
As a gov't agency, you are the solid foundation on which mountains of science are built.
It's important to performance to maintain a continuous chain of custody, and you should focus on building up from the data. But you don't need to worry about web services right now.
Folks technical enough to be accessing your data already have the network and means to analyze it.
Instead convene and consolidate under your project umbrella. Your only mission is to get new people in your club, and to be welcoming to the robots 🤖
Following that, modular and progressive design will allow you to focus development on specific goals, and bundle services from multiple orgs.
Making the infrastructure lean and decoupled, and providing tools through the web (browser) will improve accessibility. More agents will use it, and find novel applications. You can learn from this process, and ultimately provide better service.
What is the most frequent use case for these data in the ocean?
Subsea pressure sensor validation and calibration!
With offshore wind and blue economy activity, you're going to have a lot more resource constrained edge devices asking for single pixels.
Like a million? No, like a billion Voyagers, and they're gonna wander all around! I hope you are using a content distribution network.
The components that make up such a system might be:
- Cron job to checksum data sources
- Worker to process updates into S3
- S3 repository with CDN
- Optional metadata database for topology
- Durable queue
- Web worker for digitizing trajectories and array slicing
- Raster visual element
- Time series visual element
Caching is hard, and using CDNs and browsers as your runtime builds in a lot power.
Wait, the CDN is the runtime... oh no, another Cargo cult rant about Rust and Web Assembly! 🕸️🦀📦
Sort of, it doesn't actually have to be Rust. It could be C++, or even Fortran to WASM! Though the latter falls into the realm of still-way-too-hard for me.
But wait there's more!
You can put a NetCDF in S3 and read offsets directly from it! But only if you inspect the metadata once.
What if we unpack that data, move the metadata up to the browser API instead of file API, and cut out all the middle stuff?
We're using public static data, so we don't really, really need mutex, ACID, a queue, or a database.
I.f.f. we really, really want a queue, we can fallback to postgres pubsub and S3 triggers! My redis cluster makes me feel like an astronaut 👩🚀, but it is a vanity, and “no one ever got fired for choosing postgres”.
This is looks better:
- Managed S3
- Web Hook
- Web Worker
- Component
If only you could do 2D canvas in workers in Firefox. You can still output an ArrayBuffer, so it's not a huge deal… but why is the web so weird? 🧞
So, we can fetch and process a bunch of data in parallel on the client, why would we want to?
Remember how I said that the JPL tool was great because it allowed people to choose their own colors?
Depending on your precision and range, RGBA images can encode 1-8 separate dimensions, in addition to implicit x, y.
The same is true for video, saved as a “file” or generated at runtime (computer graphics). Like GOES-16.
WASM, WebGL and GLSL are available in workers, and the graphics processing unit speaks “image data” fluently.
And if the client doesn't support it, we can fallback on a polyfill in a cloud function. Or, an embedded device.
You fetch all of the assets and code needed to produce the ”data”.
Meaning you can re-parameterize, interactively, with feedback. You can dynamically patch the process in real-time, like Voyager.
The compiler catches most mistakes. And because WASM memory is contiguous, it is sand-boxed and "safe". Meaning that data structures dynamically optimized for your chunk of data don't need to be serialized. The binary is the payload and kernel.
It could be a trained statistical model that outputs some data which are close enough.
Don't trust those pesky scientists down the hall? Put in your own assumptions!
You can push this to the logical extreme, and make an arbitrarily large DAG that accounts for all inputs, products, and methods.
Is this blockchain? I don't know! But people at Berkeley think so, and tied volunteer computing to crypto-tokens with monetary and collectible value. OpenEarth is doing it for climate finance, so is Regen.Network.
To most people NASA is a lifestyle brand.
But what if every consumer wearing the NASA logo was also a node in your supercomputer, and contributed meaningfully to the scientific mission, knew they were doing so, and "bragged” about it on the Internet.
Our abstraction now encompasses the full system, while allowing for play. Play and transparency is how we learn trust. It's no longer about ”correctness”, it's about being reproducible and scalable.
A happy side effect is that you have almost no compute or storage costs.
Another is that you don't have collaborators publicly say “the updated climate down-scaling parameters made all our ecosystem projections wrong”. (April 23, 2021)
They will instead say “Oh wow, climate down-scaling parameters were updated last night, look at how X induces a positive feedback loop in wildfire frequency. Let's see what can we do about it”.
Thank you, questions?
This is partly inspired by music! It was the NASA page that inspired that, with their trivia references.
Specifically the songs Wannabe by The Spice Girls (1994), Honest Expression (2000) by Binary Star, and Pentagram Constellation (1999) by Agoraphobic Nosebleed.
Pentagram Constellation is in turn inspired by the Canadian cult film Cube (1997), in which, like the story of Icarus and Daedalus, some mortals get in trouble because they built something too complex and didn't trust each other. Cube 2: Hypercube was born the same year as GRACE (2002).